Kindle Scraper的使用教程请见:Kindle Scraper使用指南。
本文简要地记录一下代码的逻辑,以便之后回顾、理解并优化,也欢迎有兴趣的朋友讨论和修改。
原生笔记My Clippings.txt的问题:
- 强制按照时间顺序生成笔记。这样造成的问题有:
- 标注不根据书本页码和章节排列,有可能多次前后颠倒;
- 如果同时看很多本书,笔记会被不同的书拆散;
- 自动生成的笔记格式冗余信息过多,不符合大多数人的记录习惯;
- 每条都需要手动复制粘贴到个人笔记本;
- 每条都需要手动修改格式;
- 无法识别重复的笔记
- 删除并重复划线会导致重复的笔记,需要手动检阅删除;
Kindle对于购买书籍的笔记整理功能是不错的,可以在自己的账户导出需要的格式。但是对于个人文档就不支持了。如果笔记数量不多,那这些问题还是可以忍受的。但是随着用Kindle的时间增长,笔记数量不可避免地增多之后,手动整理就非常浪费时间,异常痛苦。
鉴于Kindle的笔记格式虽然多种多样,并不十分统一(呵呵)……但是仍然有迹可循,所以我想尝试用Python的方式来整理数据并导出。
网上一搜,发现英文系统的有不少人写过,思路不一,但是都无法简单修改并应用到中文系统。我挑了一个思路清晰整洁的代码kindler作为我的baseline,基于他的代码结构进行修改。
修改内容:
- 加入Kindle中文系统的适配;
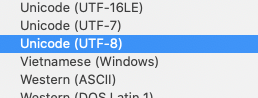
- 改用可以encode UTF-8的语法来读写文件;
- 根据中文格式修改细节(见后面ParseDetails内容)。
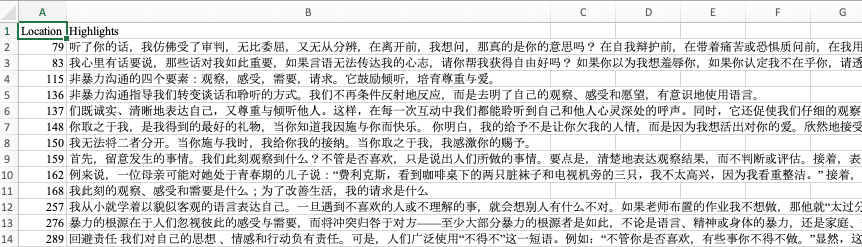
- 加入笔记的位置信息location,方便日后在Kindle中回顾前后文;
- 加入informationFrom(title),return tuple(locations, highlights);
- 将locations和highlights一并写入导出的.txt和.csv.
- 一本书内,根据locations排序所有的highlights:
- 在informationFrom(title)中sort数据
- 优化导出的.txt文件名;
- 加入titleScraper(title),生成文件前替换特殊字符。防止出现遇到特殊字符,文件不会生成也不会报错的情况;
- 加入导出.csv的功能;
- 加入importAsCsv()
- 删除Json相关功能.
重中之重ParseDetails(details):
数据整理的简要逻辑如下:
拆分行存为list -> 按delimeter所在位置判定location和highlights在list中的标号 -> 进一步简化location信息 -> location + highlights一起导出。
所有问题都出现在加粗环节。在这里我们掉过很多坑。原因在于没有想到Kindle生成的笔记格式那么不统一:导致我们在测试程序的过程中被卡住,回过头去被动地修改了很多遍。
猫认为我们应该在一开始就整理出所有不同的数据格式,而不是一次次在QA中修改。我同意,因为事后的修改因为我有点不耐烦所以conditional语句写得很没有系统性。
以下是格式相关总结:
常见格式:
========== Bliss More (Light Watkins) - 您在位置 #857-857的标注 | 添加于 2021年2月3日星期三 下午5:48:40 Focused thinking is thinking exclusively about the task at hand ==========
但并不是所有格式都如上所示。
与Location行相关的错误:
带有页码+位置信息:
========== When to Jump (Lewis, Mike) - 您在第 26 页(位置 #435-438)的标注 | 添加于 2019年7月30日星期二 下午1:53:35 With each new conversation, my voice gained confidence. Another older coworker put it bluntly: “Do you believe in yourself?” I said I did. “Who is responsible for how this jump turns out?” I said I was. “Then you have no risk in trying. You’re betting on yourself here. And you believe in that bet. You have no risk.” ==========
只有页码信息,没有位置信息:
========== 自救指南 - 您在第 18-18 页的标注 | 添加于 2014年10月26日星期日 下午3:30:48 不管神经衰弱是轻还是重,恐惧都是其发生的根源。冲突、悲伤、内 疚或羞耻可能引发神经衰弱,但恐惧很快就后后来居上 ==========
笔记信息:
========== Kindle Paperwhite 用户指南(第 2 版) (亚马逊) - 您在位置 #404 的笔记 | 添加于 2014年4月8日星期二 上午11:03:58 试用 ==========
解决办法:更细致的筛选。split字符串之后的list标号需要修改。
与Highlights相关的错误:
没有Highlihgts的书签信息:
========== 反脆弱--从不确定性中获益 - 您在位置 #657 的书签 | 添加于 2014年4月9日星期三 上午8:03:15 ==========
没有Highlights的标注(可能是Kindle的Bug):
========== Bliss More (Light Watkins) - 您在位置 #891的标注 | 添加于 2021年2月3日星期三 下午5:48:06 ==========
解决办法:如果highlights为空,则不导出。
之后可以打磨的地方:
- 继续打磨parseDetails(details)功能:简化、理清conditional语句。之后能同时使用英文和中文系统。
- 在导出的.csv 文件中加一列来区分:标注、笔记、书签;
- 加上UX部分,把数据处理部分放到后台,做成一个简单的网页工具,可以适用于不会用Github和Python的人群。不过:
- 类似的产品有一些,可能只是做自己练习使用;
- 不适用于不喜欢上传隐私信息的用户。
谢谢阅读。